ps:好像有些莫名的bug,刚写完测试时没问题,但是刚刚再测试发现好像有些bug会导致某些题目爬取出错,在助教评审时连前五十道题都没爬出来就很怪。也没精力再去更改了。
背景
为了更好地提升代码能力,jason哥想要收集相应的题目,有针对性地刷题。而需要收集洛谷所有题目,但是工作量太大,所以jason哥急需大家运用爬虫技术,得到洛谷各种难度的题目和题解。考虑到近来流行的AIGC技术,jason哥认为,在AI的帮助下,这项工作的难度会大大降低。
项目
项目的前端是利用tkinter配合gpt进行书写的,界面普普通通,长这样:
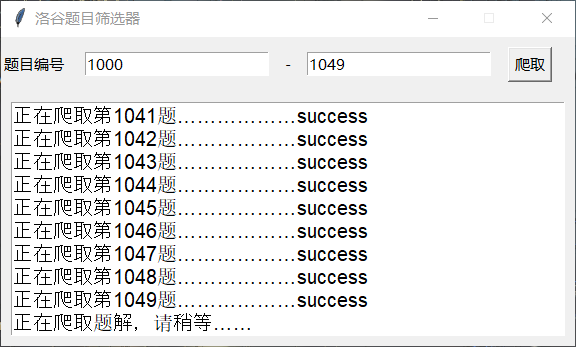
简洁明了。实际上本来想要加一些图片的,但是奈何时间不允许啊。
在爬取界面默认是爬取前五十道题题目,可以删掉进行更改为自己想要爬取的题目编号范围。点击爬取后会有文字输出,爬取完毕会跳转到筛选界面。
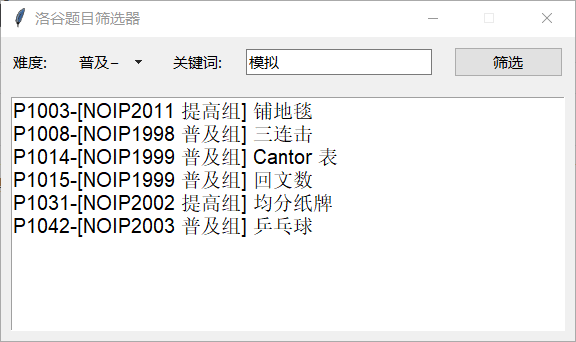
对于筛选界面也很简单,唯一一个我觉得特别一点的就是双击题目会打开题目对应的文件夹,这也是我对于作业要求中 “对于爬取的所有题目,将其”题目编号-标题“文件夹放到“题目难度-关键词”的目录下” 的理解吧,我认为这就是目录,双击就能打开。
对于按照难度和关键字进行搜索的功能,我采用的是字典加上遍历比较的方法,第一层先提取出相应难度的题目列表,然后遍历题目列表,在其中运用双重循环查看当下的题目在所有的关键字对应的题目列表中。就……挺暴力的。好在题量小也不会需要很长时间。
当然也是可以多次筛选的,这边有个问题就是我没有编写关键字的异常检测,来不及了……
在这次项目中主要运用的就是那些常规爬虫需要的技术,bs4、selenium、re等等python的库。
在爬取题解时我一开始用的是selenium配合ddddocr进行验证码识别登录,但是后面经过同学的指导,成功的实现了cookie登录,时间上是快了很多的。
单元测试:
针对单元测试,我做的是unittest。我本来想说直接利用mock对整个程序的界面进行模拟输入测试,但是调试了半天搞不明白,一直报错,属实无奈。最终我把筛选的核心逻辑函数挑选出来进行单独测试,一共有五个测试点。实际上多设置几个点,然后让他随机搭配难度和关键字,应该会得到更全面的测试,但是我感觉我的程序是没有问题的。
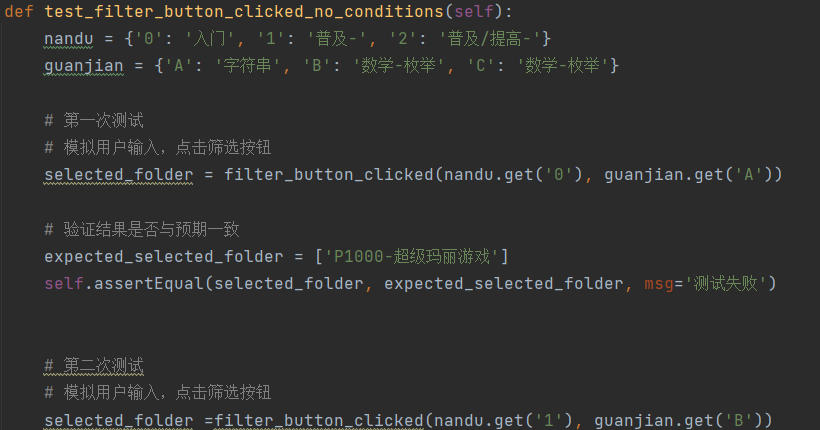
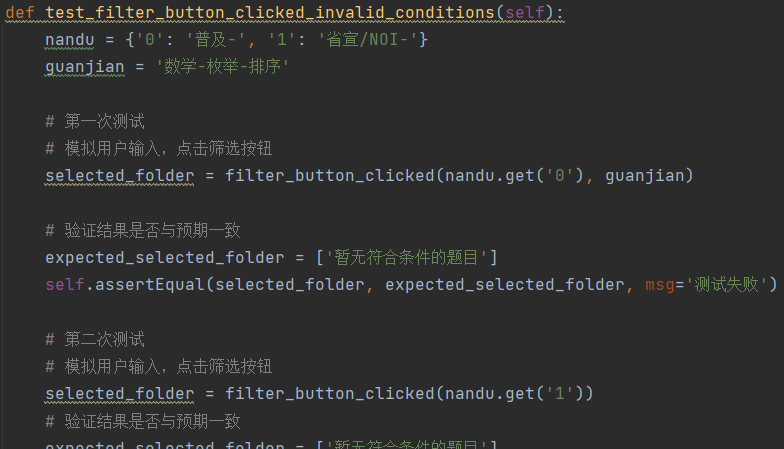
最终是测试通过了:
AIGC:
| 子任务 | 预估哪些部分使用AIGC | 实际中哪些部分使用AIGC |
|---|---|---|
| 爬取题目并保存 | 总体框架,文件保存 | 总体框架,文件保存 |
| 爬取题解 | 总体框架,文件保存,第一篇题解的提取 | 总体框架,文件保存 |
| 爬取标签关键词 | 总体框架 | 无 |
| 制作GUI界面 | 整体GUI界面框架,最终的UI美化 | UI美化 |
| 总结 | 还是不太习惯使用AIGC,在实际使用中很多时候跳出的代码语句与我想要的不一样 |
体会:
只能说非常后悔,没能把前端和爬虫的视频坚持看完,两个视频都看了一半了,尤其前端,跟着视频也写了非常多的实例代码,但是今年暑假没能坚持,没想到这么快就吃到苦头了。这几天最重要的体会就是:累鼠咯~~~建模国赛难度就是不一样,周日刚搞完建模,周一立马就转向作业,连轴转的感觉很充实就是了,有一种涤荡心灵的作用。我觉得这次作业学会最多的不是知识层面的,而是精神层面的,抗压能力和学习能力都大幅度提升。当然其实本质还是因为菜,不然也不会搞这么久就是了。
PSP:
| 项目开发阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 初步思路 | 30 | 5 |
| 爬题目 | 180 | 240 |
| 爬题解 | 180 | 360 |
| 爬标签 | 60 | 80 |
| 写前端 | 180 | 180 |
| 博客撰写 | 120 | 100 |
| 合计 | 750 | 965 |
个人评价:
实际上我理想中的项目应该是还要多很多东西的,至少也要有完善的异常检测机制,不过能做成这样也在接受范围之内了。我觉得这次的搜索界面和双击打开相应文件夹是做的比较好的,单元测试做的也算是比较完善了。对于筛选界面我是觉得应该没什么问题的,至少是能够满足要求的。。不足就在于容易出bug,还有就是我的cookie是要人为手动去复制粘贴的,并能完美的结合在一个函数中。还有就是没能空出时间针对爬虫程序设计并行算法,这个还是蛮想做出来的,这样子运行速度大幅度提高。还有就是copilot也没学会怎么用,实际上使用的不是很多,主要还是gpt用的比较多,毕竟在我们的建模队伍里我充当的是gpt调教手(代码)。
